The MAIN table is a critical entity in the data model to be used for the ALMA archive because it links the science data with all the rest. In this note I explore an alternate design to the currently proposed MSM/EDF Main table. The objective in this investigation is to minimize the translations from upstream in the Telescope Domain to downstream in the Science Domain.
The MeasurementSet (MS) is a representation of a data model (MSM) for radio data in general. This data model is described in a document (MSv2.0, Kemball and Wieringa 2000). The EDF discussion document re-uses this data model in the context of ALMA. For this purpose it has been necessary
Using the terms of Science Data Model (SDM) and Export Data Format (EDF) as defined by Doug in
the Data Capture Discussion, I would say that the MS which is a representation of the MSM is an
EDF while the MSM is a SDM. A representation goes with the use of a technology (e.g. XML, FITS,
MS as an implementation of the MSM for AIPS++) while a model provides a conceptual schema
including the exact definitions of all entities with their attributes and the relationships between these
entities..
In his discussion about Data Models and Data Flow Optimization ( Data Model Flow) Andreas
considers the Input Data Model (IDM) which belongs to the “telescope domain” as defined by Doug,
the Storage Data Model which belongs to the “science domain” and the Output Data Model (ODM)
also in the “science domain”.
An ODM is a data model which fulfils user requirements with a specific view. In this respect the
QuickLook, Pipeline and ALMA Offline sub-systems will all use the MSM as their ODM with a
science view. In the EDF discussion document, with Robert, we think that the “ALMA exported data
model should also be used in the Science Archive”. In other words and to a large extent we
are recommending that the ODM and the Storage Data Model should be as close as
possible to avoid expensive translations which could impact on data flow performances
and software complexity. In this context the acronym SDM could mean the Science
Data Model as well as the Storage Data Model, at least when restricting to its science
part.
As indicated by Andreas, the data models adopted by the different sub-systems (IDMs) should be
also as consistent as possible with the SDM to avoid expensive conversions. Those conversions, when
necessary, are made in the DataCapture which is the interface between the telescope and science
domains.
As a guideline I think that we should tend to a general design which minimizes as much as possible
the number of data models. Unjustified complexity must be avoided at all stage in the flow upstream
in the Telescope Domain to downstream in the Science Domain. This will make the life easier for the
maintenance of the model(s) and higher reliability. I do not mean that we must enforce the IDMs,
SDM and ODM to be identical! As said by Doug the SDM and ODM may evolve independently from
the IDMs in the future for good reasons but at the starting point closer are these models better it
is!
Following that objective the definition of the Correlator Data Stream has evolved with a significant reordering of the
binary data1
such that the DataCapturer do not need to transpose these binary data published by the correlator
sub-system. Although this is a clear improvement it must be realized that these published binary
data which come together with header informations which do not match yet the SDM.
Should the DataCapturer translate this stream such that it satisfies the SDM which is
identical to the ODM or should it keep it as it is received from the correlator sub-system?
This question needs discussion. If there is no translation not only this implies that the
translation would have to be done between the SDM and the ODM (this tasks would be
assigned to the fillers of Science Software packages which use the MSM) but this could also
impact on the flexibility and performance when querying these correlator data in the
archive.
In the following sections I discuss two alternatives, the first which is the SDM as it is presented in the EDF discussion document, i.e. with its MAINtable based on a legacy of the MSv2.0 MAIN table and the second with properties which minimize the translation in the DataCapture. For this discussion I’ll reuse several terms which come from the world of data bases and objects; all these have a precise meaning that I already described2.
One tuple in this MAIN table consists of a reduced number of keys, a few non-key
attributes and a data cell. There is one tuple per antenna pair (or per antenna for the
single-dish data). This is expressed by the ANTENNA1, ANTENNA2 attributes. On equal
foot appears the key TIME. As noticed in the EDF discussion document one of the
unprecedent feature with the ALMA interferometer is its large number of instantaneous
baselines, 2016 baselines for all the cross-correlations involving 64 antennas. This means
that this MAIN table will have series of tuples all coming with the identical TIME
(and INTERVAL) values. In fact the size of a series will not be simply the number of
baselines but the product of this number with the number of spectral-window/polarization
configurations, each such configuration having its own DATA_DESCRIPTION_ID key
identifiers. Having at the same level the TIME and ANTENNA1,ANTENNA2 pair is indeed
convenient because changing of TIME is equivalent to changing of baseline projection due to
the Earth rotation. With a large number of instantaneous baselines the TIME key will
play a relatively less important role in this context, especially when ALMA will have
its antennas in a compact configuration. In this case the TIME key will carry more a
notion of repeat to increase sensitivity (an increased number of exposure). Obviously
this remark is less significant when the antenna will be in extended configurations. It
is even completly irrelevant when the TIME dimension is used to study astronomical
sources with time variabilities but this will most likely concern a minority of scientific
project.
Based on these comments I conclude that the descriptive roles covered by the TIME key are
somewhat displaced in their relative impacts in a situation with an interferometer with a small
number of antennas and spectral-window/polarizion capabilities, as it is the case with the existing
interferometers compared to an interferometer like ALMA.
In addition to this it must be noticed that this MAIN table has a SORT_ORDER
in its keywords. The data being archived with a fixed order, the ascending time, this
MAIN table cannot yet be considered as organized in an efficient form for imaging
because this still requires re-ordering when griding. Indeed the TIME key remains of
primary importance not only before the calibration of the data but also subsequently
for diagnostics on instrumental effects (e.g. receiver instabilities, weather instabilities
etc...).
Let now consider the data stream published by the correlator sub-system. All the data
corresponding to a given time-stamp are received in one block to which will be assigned an
identifier.
In the correlator ICD document we see that the actual binary data come with a header in which
there are mostly sizes to describe the multi-dimensionnality of the data, explicitely per baseband, the
numbers of polarization products, of sub-bands, of frequency channels for each sub-band, of baselines
(cross and self products), of correlator data bins and if there is both the visibilities uncorrected and
corrected to account for the atmospheric phase fluctuations using the radiometric measurements. In
addition to this the data size in number of bytes is also given for the cross and the self
products. These data will be received for all the basebands, interleaving at this level in the
data block a baseband index with its center frequency, a time stamp and an integration
duration3.
Taking all these numbers into consideration together with these few inter-leaved quantities, it is
possible to implement methods to access any piece of the data corresponding to a well defined region
in the parameter space.
The only two descriptive non-key data which are generated by the correlator sub-system are there,
coming with the data themselves.
The links of the correlator data with their relevent meta-data descriptioni are however not present.
The correlator sub-system publish an “integration header” which consists of 4 attributes including 3
identifiers. These 3 identifiers are EXECUTE_ID, SCAN_ID, OBSERVATION_ID. The last
attribute, named in the ICD integrationID, is an enumeration; it is strictly identical to the attribute
INTEGRATION_NUM of the EDF MAIN table. This “integration header” is the top level of the
correlator IDM.
This “integration header” is not sufficient to establish the links between any piece of correlator data
with their corresponding meta-data informations. Making this link requires defining
tables which would be an alternative of the MAIN table in the data model. In the EDF
document we wanted to initiate a discussion when noticing that the model as presented
could be “too much baseline based”. The data cell published by the correlator is not
baseline based, actually neither spectral_window/polarization based; all the data coming
out of the correlator are put in the data cell, this for a given correlator configuration
(connection to the antennas, spectral and polarization cross product setups) for a given
sub-array4.
To develop further this discussion I now explore what could be these tables if we consider the data
cell of the correlator IDM instead of the SDM data cell which complies with the MSM Data Cell of
the MAIN ODM table.
The layout of the CONFIG_DESCRIPTION is given in Tab. 1.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
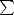 1Nbb(Nbi ×Nsb).
All the collections in this table are arrays of identifiers. The collections must be ordered and
any identifier must appear only once in a collection).
1Nbb(Nbi ×Nsb).
All the collections in this table are arrays of identifiers. The collections must be ordered and
any identifier must appear only once in a collection).
Not surprisingly, this table to a large extent contains the attributes of the “correlator data integration stream header” in the CORRELATOR ICD. The attributes in the Data description section gives explicitly some of the axis sizes which are needed to describe the form of the data cell (the binary part of the correlator stream). The sizes which are not expecitly there are implicit due to the encapsulation of the DATA_DESCRIPTION_IDidentifiers members of the DATA_DESCRIPTION_ARRAY collection in the Data section. The role for these sizes is to be able to have a method to access directly any fragements as desired in the content of the data cell, e.g. selecting the data for a given spectral window/polarization, the data corresponding to a subset of antenna, the single-dish data exclusively an so forth. This CONFIG_DESCRIPTION table does not contain only the header informations published in the correlator stream, it also tells completely e.g. what are the antenna involved for each cross or auto-product. This table provides a full description of how the correlator is connected with the antenna together with the spectro-polarization configuration. In other words it fully describes the correlator configuration. As such this specifies the referential constraint in the Telescope Domain.
The layout of the DRAFT_MAIN table is presented in Tab. 2.
The temporal granularity in this DRAFT_MAIN table remains at the level of an INTEGRATION or sub-integration. Comparing with the MSM MAIN table, notice that the SWITCH_PHASE_IDidentifier has been removed. Although the SWITCH_PHASE table has not yet been designed, I think that one correlator bin will correspond to one SWITCH_PHASE_ID. Since all the correlator bins are now present in the data cell, a collection of SWITCH_PHASE_IDmay have to be added in the Data section of the CONFIG_DESCRIPTION table.
The PROCESSOR_IDidentifier of the MSM ODM MAIN table is now put in the CONFIG_DESCRIPTION table because the configuration depends on the hardware capabilities of the processor.
Within an observation unit several sub-arrays may operate in parallel, eventually in sync.
It is quite convenient to account for this fact with a CONFIG_DESCRIPTION table, each
sub-array in that table being described by a single tuple. For this reason DRAFT_MAIN
table does not need of a SUBARRAY_NUM attribute, the different sub-arrays being
distinguishable via their different CONFIG_DESCRIPTION_IDidentifiers.
In this new design the identifier FIELD_IDis still in the MAIN table. This introduces a
dichotomy between the two types of sub-arrays, those for observing simulatneously with
several spectro-polarization configurations and those for several directions on sky (indeed
this does not prevent to have e.g. two sub-arrays each with their own specto-polarization
configuration and their own pointing direction). Should this dichotomy be characterized by
involving two entities in the data model or should it involves only a single entity? I do not
think that splitting these concepts of sub-arrays is a real problem! With the proposed design
the CONFIG_DESCRIPTION table has the advantage to remain small and
static.
The EXECUTE_SUMMARY table contains an ANTENNA_LIST attribute. In this
new context this collection which is of type “set” (1/ elements not required to be in a
specific order and 2/ the elements must appear exclusively once) would correspond to
the union of the ANTENNA_ARRAY collections. Hence it has to be renamed
CONFIG_DESC_SET with a form (NUM_SUBARRAY), each element being a
CONFIG_DESCRIPTION_IDidentifier. Then the other attributes, BASE_RANGE,
BASE_RMS and BASE_PA have also to take the form (NUM_SUBARRAY).
The correlator ICD had a subArrayID which is not present in the last version. This
information should be kept to allow differenciating two sub-arrays operating
in sync with the same number of antennas and the same spectro-polarization
configuration, the only difference being that each sub-array would be used with a
different FIELD_ID. This subArrayID would be the CONFIG_DESCRIPTION_ID
identifier.
The data cell: In this DRAFT_MAIN table the attribute for the data cell appear as an object identifier (OID). The technical method is TBD. Examples are e.g. techniques of pointer swizzling or virtual memory to provide access to the object. Since all the information is available to select any piece of data in the data cell (selection on antennas, on basebands, on subbands and so forth) it must be possible for the archive user to use expressions of methods to access the object, one of the important operation being to filter and unnest the object to build something like the MSM MAIN table. Indeed it must be possible to select, e.g. in the context of the Quick Look, a single spectral channel of a given sub-band in a baseband to extract the corresponding data with all the baselines to produce a dirty image.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||